지금까지 버블 정렬, 선택 정렬, 삽입 정렬 같은 많은 정렬 알고리즘을 살펴봤다. 하지만 실제로 배열을 정렬할 때는 이러한 방법을 쓰지 않는다. 컴퓨터 언어 중 대다수가 내부적으로 채택한 정렬 알고리즘이 있는데 바로 '퀵 정렬(Quicksort)'이다.
퀵 정렬의 동작 방식을 공부하면 재귀를 사용해 어떻게 알고리즘의 속도를 크게 향상하는지 배울 수 있다.
퀵 정렬은 매우 빠른 정렬 알고리즘으로 특히 평균 시나리오에서 효율적이다. 최악의 시나리오(즉, 역순으로 정렬된 배열)에서는 삽입 정렬이나 선택 정렬과 성능이 유사하지만 대부분의 경우 일어나는 평균 시나리오에서는 훨씬 빠르다.
퀵 정렬은 '분할(partitioning)'이라는 개념에 기반하므로 분할을 먼저 알아보자.
12. 1 분할
배열을 분할(partition)한다는 것은 배열로부터 임의의 수(피벗(pivot)이라고 부름)를 가져와 피벗보다 작은 모든 수는 피벗의 왼쪽에, 피벗보다 큰 모든 수는 피벗의 오른쪽에 두는 것이다.
만약 아래와 같은 배열이 있다고 보자.

피벗은 가장 오른쪽에 있는 값으로 삼겠다(물론 다른 값을 골라도 상관없다).
예제에서는 숫자 3이 피벗이다.

이어서 두 '포인터'를 사용해 배열 가장 왼쪽에 있는 값에, 다른 하나는 피벗을 제외한 배열 가장 오른쪽에 있는 값에 할당한다.
그리고 왼쪽 포인터를 한 셀씩 계속 오른쪽으로 옮기면서 피벗보다 "크거나 같은 값"에 도달하면 멈춘다. 그렇지 않으면 오른쪽으로 이동한다.
이어서 오른쪽 포인터도 한 셀씩 계속 왼쪽으로 옮기면서 피벗보다 "작거나 같은 값"에 도달하면 멈춘다. 또는 배열 맨 앞에 도달해도 멈춘다. 그렇지 않으면 왼쪽으로 이동한다.
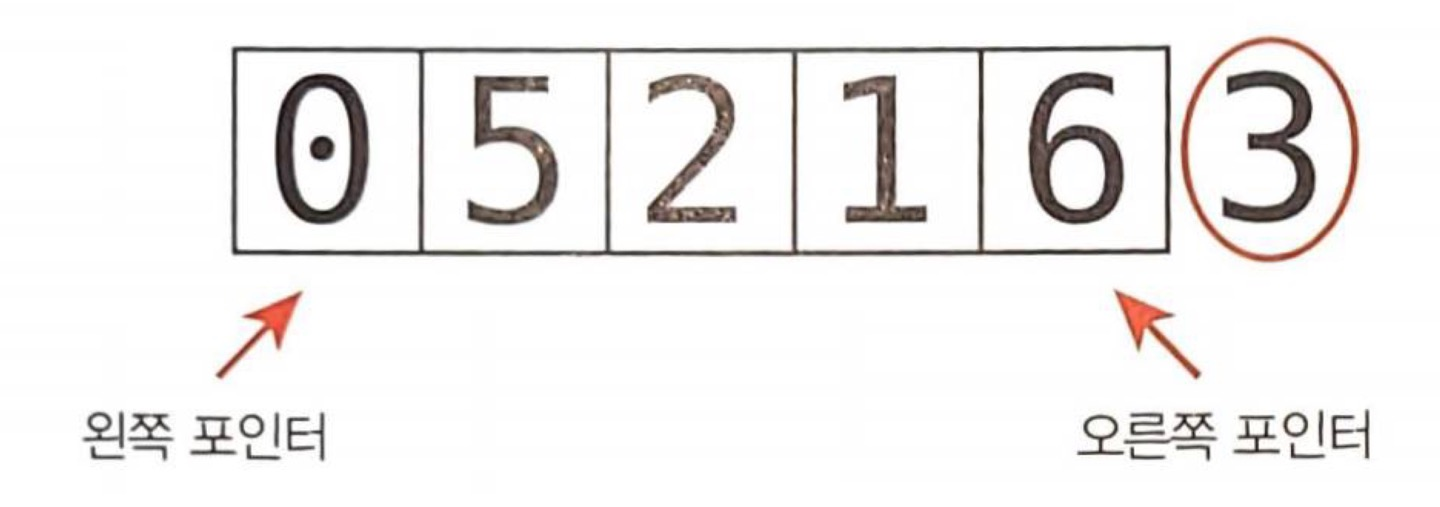
왼쪽 포인터(현재 0을 가리킴)와 피벗(값 3)을 비교한다. 0은 피벗보다 작으므로 다음 단계에서 왼쪽 포인터를 옮긴다.

왼쪽 포인터(값 5)와 피벗을 비교한다. 5가 피벗보다 "크기 때문에" 왼쪽 포인터를 멈추고, 다음 단계에서 오른쪽 포인터를 이동시킨다.
오른쪽 포인터(값 6)와 피벗을 비교한다. 오른쪽 포인터 값이 피벗보다 크므로 포인터를 왼쪽으로 옮긴다.

오른쪽 포인터(값 1)와 피벗을 비교한다. 1이 피벗보다 "작기 때문에" 오른쪽 포인터를 멈춘다.
두 포인터가 모두 멈췄으니 두 포인터의 값을 교환한다.
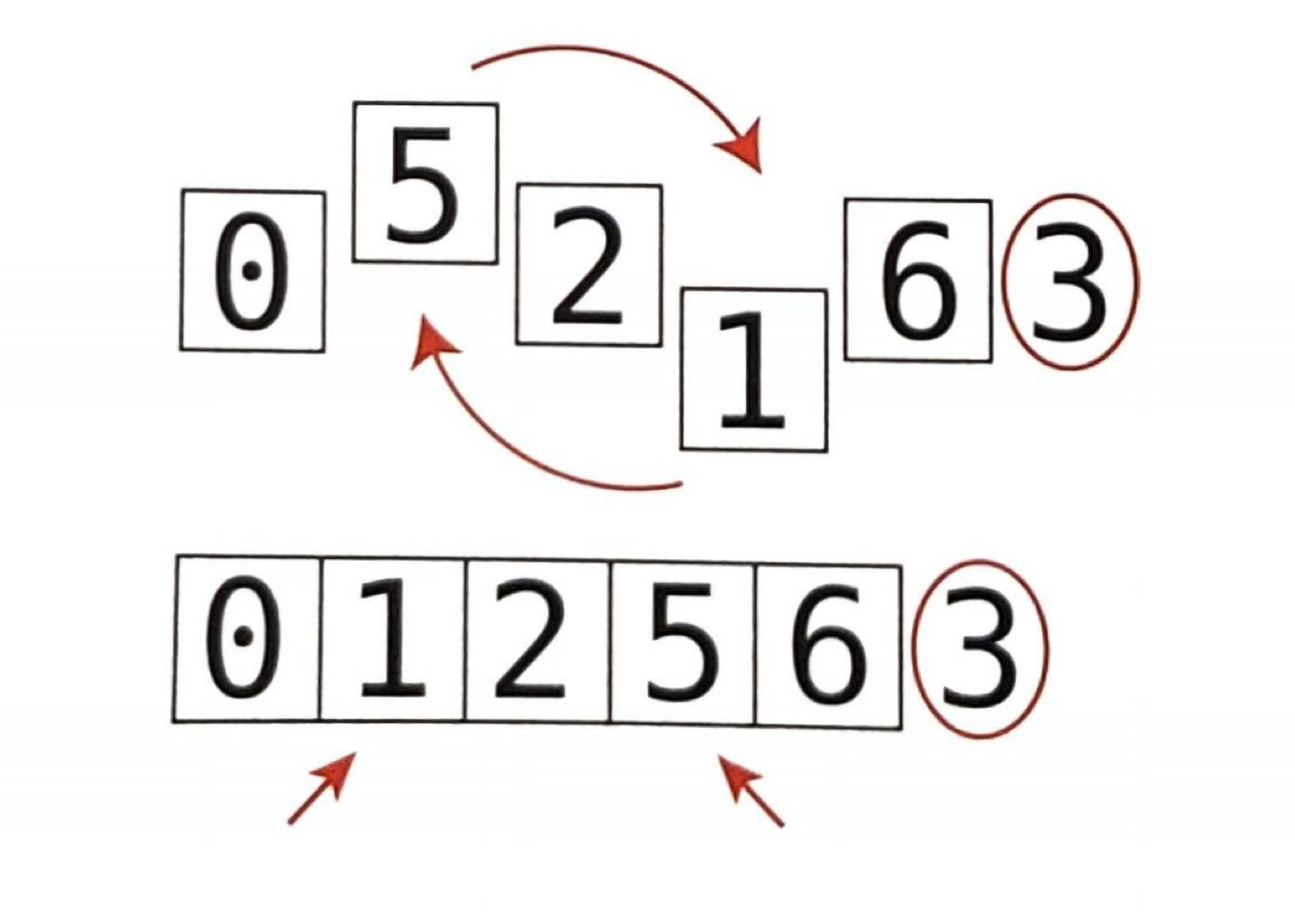
다음 단계에서 다시 왼쪽 포인터를 이동시킨다.

왼쪽 포인터(값 2)와 피벗을 비교한다. 2가 피벗보다 작아서 왼쪽 포인터를 계속 옮긴다. 그러면 왼쪽 포인터와 오른쪽 포인터가 모두 같은 값을 가리킨다.

왼쪽 포인터와 피벗을 비교한다. 왼쪽 포인터가 피벗보다 큰 값을 가리키고 있으므로 멈춘다. 이때 왼쪽 포인터가 오른쪽 포인터에 도달했으므로 포인터 이동을 중지한다.
분할의 마지막 단계로서 왼쪽 포인터가 가리키고 있는 값과 피벗을 교환한다.
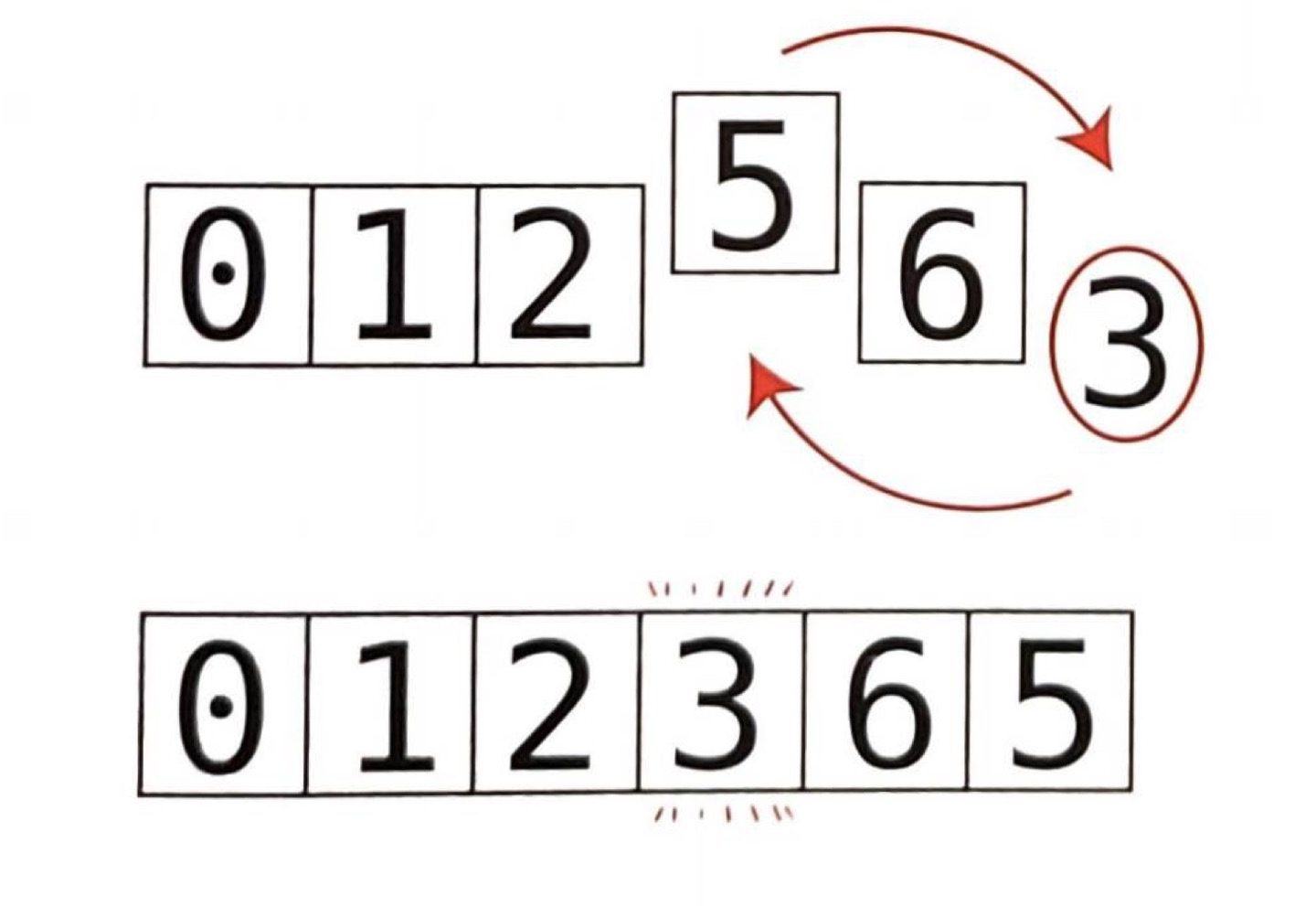
배열은 완전히 정렬되지 않았지만 분할은 성공적으로 끝냈다.
즉, 피벗이 숫자 3이었으므로 3보다 작은 모든 수는 3의 왼쪽에, 3보다 큰 모든 수는 3의 오른쪽에 있다. 또한, 3이 이제 배열 내에서 올바른 위치에 있게 됐다.
12. 2 퀵 정렬
퀵 정렬 알고리즘은 '분할'과 '재귀'로 이뤄진다.
(1) 배열을 분할한다. 피벗은 이제 올바른 위치에 있다.
(2) 피벗의 왼쪽과 오른쪽에 있는 하위 배열을 각각 또 다른 배열로 보고, 1단계와 2단계를 재귀적으로 반복한다. 즉, 각 하위 배열을 분할하고 각 하위 배열에 있는 피벗의 왼쪽과 오른쪽에서 더 작아진 하위 배열을 얻는다. 이어서 이러한 하위 배열을 다시 분할하는 과정을 반복한다.
(3) 하위 배열이 원소를 0개 또는 1개 포함하면 기저 조건이므로 아무것도 하지 않는다.
위에서 한 번 분할을 수행했던 배열을 다시 보자.

값 3이 피벗으로 올바른 위치에 있다.
이제 피벗의 왼쪽과 오른쪽을 정렬해야 한다.
분할이 끝나면 다음으로 피벗 왼쪽에 있는 모든 값을 하나의 배열로 보고 분할한다.
하위 배열 [0, 1, 2] 중에서 가장 오른쪽 원소를 피벗으로 삼겠다. 즉, 숫자 2다.

왼쪽과 오른쪽 포인터를 설정한다.

왼쪽 포인터(0)와 피벗(2)을 비교한다. 0은 피벗보다 작으므로 왼쪽 포인터를 옮긴다.
그러면 왼쪽 포인터와 오른쪽 포인터가 같은 값을 가리키게 된다.

왼쪽 포인터와 피벗을 비교한다. 값 1은 피벗보다 작으므로 포인터를 오른쪽으로 한 셀 옮긴다.
이제 왼쪽 포인터는 피벗을 가리키게 된다.

이때 왼쪽 포인터가 가리키는 값이 피벗과 동일하므로 왼쪽 포인터를 멈춘다.
오른쪽 포인터를 동작시킨다. 하지만 오른쪽 포인터의 값(1)이 피벗보다 작으므로 그대로 둔다.
왼쪽 포인터가 오른쪽 포인터를 지나쳤으므로 이번 분할에서는 더 이상 포인터를 이동시키지 않는다. 다음으로 피벗과 왼쪽 포인터의 값을 교환하는데, 우연히 왼쪽 포인터가 피벗을 가리키게 됐으므로 피벗 자신을 교환한다. 따라서 아무런 변화도 없다.
이제 분할이 끝났고 피벗(2)은 올바른 위치에 놓였다.

이런 식으로 하위 배열에 피벗을 정하고 '분할'을 재귀적으로 수행하면 모든 피벗이 올바른 위치에 갈 것이다.
12. 3 퀵 정렬의 효율성
퀵 정렬의 효율성을 알아내려면 한 번 분할할 때의 효율성을 밝혀야 한다.
분할에 필요한 단계는 두 종류다.
- 비교: 각 값과 피벗을 비교한다.
- 교환: 적절한 때에 왼쪽과 오른쪽 포인터가 가리키고 있는 값을 교환한다.
각 분할마다 배열 내 각 원소를 피벗과 비교하므로 최소 N번 비교한다. 분할을 한 번 할 때마다 왼쪽과 오른쪽 포인터가 서로 만날 때까지 매 셀을 이동하기 때문이다.
하지만 교환 횟수는 데이터가 어떻게 정렬되어 있느냐에 따라 다르다. 가능한 값을 모두 교환한다 해도 한 번에 값 두 개를 교환하므로 한 분할에서 최대 N / 2번 교환한다.
아래 그림처럼 원소 6개를 3번의 교환으로 분할한다.

대부분의 경우 매 단계마다 교환이 일어나지는 않는다. 무작위로 정렬된 데이터가 있을 때, 일반적으로 대략 값의 반 정도만 교환한다. 즉 평균적으로 N / 4번 정도 교환한다.
따라서 평균적으로 N번 비교하고, N / 4번 교환한다. 결과적으로 원소가 N개일 때 대략 1.25N단계가 걸린다. 하지만 빅 오 표기법은 상수를 무시하므로 O(N) 시간에 분할을 실행한다고 볼 수 있다.
이는 한 번 분할할 때의 효율성이다. 퀵 정렬은 여러 번 분할하므로 퀵 정렬의 효율성을 알아내려면 좀 더 분석이 필요하다.
만약 원소가 8개인 배열에 대한 퀵 정렬을 하면 다음과 같이 수행된다.

총 8번 분할하는데 분할할 때마다 하위 배열의 크기가 다르다. 원소가 8개인 원래 배열을 분할하고, 크기가 4와 3, 2인 하위 배열을 분할하고, 크기가 1인 배열을 4번 분할한다.
퀵 정렬은 기본적으로 연이은 분할로 수행되는데, 각 분할마다 하위 배열의 원소가 N개일 때 약 N단계가 걸린다. 결국 퀵 정렬에 걸리는 총 단계 수는 모든 하위 배열의 크기의 총합이다.

원래 배열에 원소가 8개일 때 퀵 정렬에 약 21단계가 걸렸다. 원소가 16개인 배열에 대해 퀵 정렬에 약 64단계, 원소가 32개인 배열에 대해 약 160단계가 걸린다.

해당 글은 '누구나 자료구조와 알고리즘' 책의 내용을 기반으로 작성되었습니다.
오로지 학습용으로 작성하였음을 밝힙니다.
더 자세한 내용을 확인하고 싶다면 해당 저서를 참고하시길 바랍니다.
'자료구조 & 알고리즘' 카테고리의 다른 글
| Ch.14 이진 탐색 트리로 속도 향상 (도서 요약 "누구나 자료구조와 알고리즘") (0) | 2022.06.10 |
|---|---|
| Ch.13 노드 기반 자료 구조 (도서 요약 "누구나 자료구조와 알고리즘") (0) | 2022.06.09 |
| Ch.11 재귀적으로 작성하는 법 (도서 요약 "누구나 자료구조와 알고리즘") (0) | 2022.06.07 |
| Ch.10 재귀를 사용한 재귀적 반복 (도서 요약 "누구나 자료구조와 알고리즘") (0) | 2022.06.06 |
| Ch.09 스택과 큐로 간결한 코드 생성 (도서 요약 "누구나 자료구조와 알고리즘") (0) | 2022.05.11 |



